
Gerade wenn man es eilig hat oder an einem wichtigen Projekt arbeitet, stört Spam umso mehr. Warum taucht immer wieder die gleiche Mail auf, warum filtern die Anti-Spam-Algorithmen das nicht weg? Warum es manchmal ist es schwer, gewünschte Mails von unerwünschten zu unterscheiden und man notfalls selbst etwas tun kann.
Die vielen Erscheinungsformen von Spam
Das Problem
Es gibt keine besonders gute Definition, was Spam eigentlich ist. Vermutlich ist „unerwünscht zugesandte E-Mail“ die Formulierung, auf die sich alle einigen können.
Schon bei der Ergänzung „massenhaft versandte, aber unerwünschte E-Mail“, zerfällt die Definition, zumindest aus Empfängerperspektive: Massenmails können von dem einen erwünscht sein, von dem anderen nicht.
Wir alle kennen die individuell zugeschnitten Notifications von vielen Onlineservices. Dennoch können diese Mails nervtötend werden, wenn sie redundant, zu häufig oder fehlerhaft sind. Dann empfindet sie der Empfänger oder die Empfängerin als Spam – selbst dann, wenn man als User oder Userin zunächst mit der Zusendung einverstanden war. Je nutzloser, desto eher wird man sich belästigt fühlen. Aber sind diese Mails wirklich unerwünscht und sollte man sie als Spam behandeln oder sogar sofort löschen?
Je nutzloser eine E-Mail, desto eher wird sie als Spam empfunden
Dabei ist Spam aber nicht nur harmlos, wenn auch nervig. Es gibt viele Angriffsvektoren auf Endgeräte oder Accounts, die per E-Mail starten.
Im Bereich Phishing senden die Angreifer E-Mails mit alarmierendem Inhalt. Man möge sich einloggen und ein Problem korrigieren. Will man als Angreifer einen Trojaner in ein Firmennetzwerk einschleusen, muss man den Empfänger dazu bringen, einen Mailanhang zu öffnen oder eine Datei herunterzuladen.
In vielen Fällen, die man als Spam erkennt, handelt es sich hingegen um unerwünschte Werbung, die sich dummerweise per E-Mail ohne große Kosten verbreiten lässt. Es gibt Gesetze dagegen, zum Beispiel das Telemediengesetz, doch handeln Spamversender anonym, sind nur schwer zurückzuverfolgen. Wenn die absendenden Server im Ausland stehen, wird die Strafverfolgung sehr kompliziert und die Erfolgsaussichten sind gering.
Die korrekte Klassifizierung einer Mail als Spam ist die Herausforderung für Provider
Einer internen Statistik von goneo zufolge sind fast 40 Prozent aller Mails recht eindeutig als Spam zu klassifizieren. Dazu kommen dann die Zweifelsfälle, die im einstelligen Prozentbereich liegen. Etwas mehr als die Hälfte aller eingehenden Mails wird überhaupt in die Mailpostfächer zugestellt.
Als Serviceprovider betrachtet man dabei nicht nur die große Menge an eingehenden E-Mailnachrichten. Auch bei ausgehenden Mails kann es sich um Spam handeln. Hier könnte man sich auf den Standpunkt stellen, dass dies ja egal sein könnte. Allerdings drohen dem Provider dann die Folgen von Abwehrmaßnahmen anderer Provider. Daher wird auch ausgehender Maildatenverkehr auf Spamverdacht geprüft.
Spam-Filter
Nahezu jeder Mailserver ist mit Spamfiltern ausgestattet, natürlich auch die Server von goneo. Sie sollen unerwünschte Nachrichten erkennen und in einen separaten Ordner verschieben oder ganz löschen. Filter eines E-Mailprovider müssen allerdings die Bedürfnisse aller Mail-User auf diesem Server abdecken, so dass eine Balance gefunden werden muss, wie streng die Aussortierung von vielleicht vermeintlichen Spammails gehandhabt wird.
Was du als Mail-User selbst gegen Spam unternehmen kannst
- Sei vorsichtig mit deinen E-Mail-Adressen
Gib deine Haupt-E-Mail-Adresse nicht auf öffentlichen Plattformen oder Webseiten preis. Nutze dafür alternative E-Mail-Adressen für Online-Registrierungen oder Foren. Entscheide, ob du dem Anbieter wirklich vertrauen möchtest. - Achte auf die Opt-out-Möglichkeiten
Legitime Newsletter und Werbe-E-Mails bieten eine Abmeldefunktion („Unsubscribe“). Nutze diese Option, um sich von unerwünschten Verteilern abzumelden. - Öffne verdächtige E-Mails nicht
Vermeide es, E-Mails von unbekannten Absendern zu öffnen, insbesondere wenn diese Anhänge enthalten oder wenn zu gut klingende Angebote präsentiert werden. Das deutet sehr auf Phishing-Versuche oder Malware hin. - Halte die Software aktuell
Regelmäßige Updates für das Betriebssystem, den Browser und E-Mail-Anwendungen können Sicherheitslücken schließen und die Effektivität gegen Spam verbessern. - Melde Spam
Viele Dienste bieten die Möglichkeit, Spam zu melden. Nutze diese Funktionen, um zur Verbesserung der Filteralgorithmen beizutragen. Zudem kannst du einen Service wie Appmelder nutzen, um unerwünschte Werbung zu melden.
- Nutze Filterfeatures
In vielen Webmailern wie auch bei goneo und auch Mail-Anwendungen können Regeln definiert werden. Dies kannst du nutzen, um Spammails, die immer wieder durch die allgemeinen serverseitigen Filter gelangen, auszusortieren.
So funktioniert die Unterscheidung von Mails, die man empfangen möchte
Um Spam als Spam zu erkennen gibt es viele Ansätze. Erst mit einer geschickten Kombination darauf erhält man einen funktionierende und gut automatisierbare Erkennungsmethodik. Die effiziente und maschinelle Bearbeitung ist notwendig: Bei Providern rauschen E-Mail-Mengen in dreistelliger Millionenhöhe pro Woche oder Monat durch.
Um unerbetene oder störende Mails auszufiltern, müssen viele Geschütze aufgefahren werden.
Erstens kann man versuchen, alleine durch die Struktur der Mail einige Merkmale zu finden. Dies sind inhaltliche Merkmale sowie technische
Jedes Kriterium für sich lässt keine treffsichere Einschätzung zu. Aber in Kombination kann die Treffergenauigkeit sehr hoch werden. Im Grunde werden Scorewerte aus einzelnen Spam-Kriterien additiv oder multiplikativ verrechnet.
Am einfachsten ist es noch, wenn viele Mails gleichen oder fast gleichen Inhalts in kurzem zeitlichen Abstand eingehen. Wenn dies geschieht, ist die Wahrscheinlichkeit, dass gerade eine Spamwelle rollte, nochmal höher. Allerdings braucht man dann schon eine Art „Buchführung“ über eingehende Mails und deren hohe Ähnlichkeit.
Schwierig wird es, wenn eine Mail sehr wenig Inhalt hat, den man maschinell qualifizieren könnte.
Ein Warnsignal sind Anhänge. Diese können schädlich sein, wobei Anhänge natürlich möglich sein müssen. Also sollte möglichst automatisiert untersucht werden, ob es sich um Dateien mit bekannten Schadwirkungen handelt. Allerdings braucht man auch ein Verfahren für zweifelhafte Dateien, deren Wirkung nicht absehbar ist. Vieles an Schadsoftware ist komplex und taucht immer wieder auf. So lassen sich Erkennungslisten zusammenstellen.
Wann ist Spam als Spam erkennbar?
Es kommt stets auch auf die Menge an. Reichen 100 gleichlautende Mails, um mit einiger Sicherheit von Spam zu sprechen? Sicher nicht. Es gibt viele Szenarien, die dafür sprechen, dass die Mails beim Empfänger gewollt sind: Ein Verein, der seine Mitglieder zur Jahreshauptversammlung einlädt, die Absage eines Events durch den Veranstalter und dergleichen.
Würde man diese Mails wegfiltern, wären viele Menschen sehr sauer. Also muss die Untersuchung vielschichtiger sein und feiner passieren.
Zweitens kann man auf den Inhalt der Mail abzielen und diverse Merkmale bündeln, die man in eigentlich jeder Spam-Mail findet. Bei Apache gibt es ein Softwareprojekt namens SpamAssasin. Dies ist schon recht alt und man findet es heute vielerorts meist an vorderster Front in der Spam-Abwehr. Mit SpamAssasin durchläuft jede Mail, die zu klassifizieren ist, über hundert Tests. Dabei schaut sich das Tool Mail-Header und Mail-Body an. Es prüft, ob die Absenderadresse auf einer bekannten Spamliste steht. Auch, ob die E-Mail korrekt formuliert ist und den Spezifikationen entspricht, ist ein Kriterium.
Ebenso verfährt es mit dem absendenden Server. Es checkt Konformitäten, denn auch wenn eine Mail klar als Werbung erkennbar ist, kann diese gewollt sein. Man denke nur an den regelmäßigen Sonderangebotsnewsletter mit den attraktiven Preissenkungen.
Jeder Test der vielen Einzeltests endet mit einem Ergebnis. Am Ende werden diese Einzelergebnisse zu einem Scorewert verrechnet. Das kann man sich im einfachsten Fall wie eine summarische und multiplikative Verknüpfung vorstellen.
Diese statistische Betrachtung kann man auch weiter treiben, indem man nicht nur sehr summarische oder multiplikative Modelle anlegt, sondern die Kriterien in Matrizen verrechnet. Dafür eigenen sich Methoden aus der linearen Algebra. So gelingt es, komplexere Modelle zu formulieren.
Modelle zur Schätzung von Wahrscheinlichkeiten
Natürlich müssen diese Modelle erst einmal gewonnen und validiert werden. Dann müssen diese sich in der Praxis bewähren. Das Ziel ist dabei immer, die Fehlerrate gering zu halten. Es geht darum, weder viele falsch-negative, noch zu viele falsch-positive Kategorisierungen zu erzeugen. Die Fehler sollen minimiert werden, nur darf man auch nicht über das Ziel hinausschießen.
Das Schöne an Spam ist, dass Spam nicht selten ist. Das schreit regelrecht nach künstlicher Intelligenz und maschinellem Lernen (ML). Tatsächlich ist die Spamerkennung ein Paradebeispiel für ML-Anwendungen. Dank des häufigen Vorkommens hat man genug Material, um zum Beispiel neuronale Netze zu trainieren. Man kann natürlich schneller umzusetzende Methoden verwenden wie eine Support Vector Machine.
Das Blöde an Spam wiederum ist, dass sich die Taktiken schnell ändern. So entsteht ein Katz- und Mausspiel von Spammern und Spamjägern.
Mit neuronalen Netzen kann man dennoch recht schnell auf neue Spamphänomene reagieren. Das Tolle daran ist, dass neuronale Netze so ausgelegt sind, dass sie die Kriterien selbst finden, wenn man lange genug trainiert. Allerdings braucht man für das Training dieser Netze viele Daten mit bekannten Eingangs- und Ausgangswerten. Man muss also von einer Mail wissen, ob diese schon als Spam gilt oder nicht. Und dann braucht man sehr viele davon. Je mehr, desto besser. Desto besser wird das neuronale Netz Ergebnisse liefern, im Sinne von niedrigen Alpha- und Betafehlern.
Spammer ändern ihre Taktik schnell
Im Grunde handelt es sich um „statistische Verfahren auf Steroiden“. Ob eine Mail eine Spammail ist, könnte man, um valides Testmaterial zu gewinnen, zunächst von menschlichen Bewertern einschätzen lassen.
Eine andere Möglichkeit: Man wertet das Verhalten der Empfänger aus. Wird die Mail als Spam markiert, handelt es sich um Spam. Aus diesem Paradigma leitet sich die Frage ab, wie sich Spam dann markieren lässt, heißt: Welches Userverhalten deuetet darauf hin, dass eine Mail unerwünscht, also Spam, ist? Das ist abhängig vom Endgerät oder der Software. Schnelles Löschen deutet sicher darauf hin, dass die Mail unerwünscht oder zumindest gerade nutzlos war. Eine Beantwortung oder Weiterleitung hingegen signalisiert, dass die Mail sinnvoll und gewollt war.
Möglicherweise sendet der Absender allerdings öfter mal eine E-Mail. Manche davon sind in dem Moment sinnvoll, andere nicht.
Hier erkennt man auch, dass an dieser Stelle schon durchaus Fehleinschätzungen passieren können. Vielleicht hat der User sich nur vertippt oder gerade nur diese Nachricht ist Spam, während andere Nachrichten vom gleichen Empfänger durchaus wichtig sind.
Inhaltliche Analyse
Man könnte auch inhaltsanalytisch vorgehen und eine Art „Bad word Liste“ anlegen. Mails mit entsprechendem Inhalt würde man dann blockieren oder zumindest dafür sorgen, den Score nach oben zu treiben. Aber eventuell gibt es auch User und Userinnen, die solche Mails versenden bzw. erhalten wollen.
In der Masse sollten sich Fehler ausmitteln. Im Einzelfall bedeutet dies dann aber, dass die eine oder andere Spam-Mail durch die Filter gelangt.
Für effiziente Filter braucht man recht viele Testfälle, die geonnen werden müssen. Am Ende muss man austarieren, welche Menge sinnvoll ist. Das ist im Grunde ein ökonomische Fragestellung.
Diese Erkenntnis, die sich aus dem Userverhalten interpretieren lässt, kann man dann zum Trainieren eines neuronalen Netzes verwenden. Denkbar ist es auch, die Maschine sozusagen unbeobachtet lernen zu lassen, indem man eine Art Feedbackschleife baut. Auf diese Weise gelangt man recht schnell und flexibel zu wirksamen Filtern.
Spam und eigene Gegenmaßnahmen
Nehmen wir an, eine eingehende E-Mail wurde mit hoher Wahrscheinlichkeit als Spam klassifiziert. Sie ist offenbar unerwünscht. Die Frage, die sich nun stellt: Was soll mit dieser Mail passieren?
Schon aus Mengengründen müssen Mails, die eindeutig Spam sind, gelöscht werden. Speicher ist zwar billiger geworden, aber dennoch nicht unbegrenzt verfügbar. Zweifelhafte Mails mit einem Spam-Score, der uneindeutig ist, sollten zugestellt werden. In solchen Situationen würden sich mit einiger Wahrscheinlichkeit negative Konsequenzen ergeben, würde man die Mails nicht zustellen. Unter Umständen könnte man solche Mails extra kennzeichnen oder in ein bestimmtes Verzeichnis verlagern.
Warum „Wegwerfadressen“ keine gute Lösung sind
Hin und wieder wird empfohlen, nur eine „Wegwerfadresse“ zu nutzen, um sich bei irgendeinem Service anzumelden. Solche Mailadressen sind nur kurzfristig gültig und sobald man das Mailpostfach bestätigt hat, was viele Services fordern, wird die Adresse wieder deaktiviert.
Für die Erstanmeldung wird das reichen, doch irgendwann kommt der Moment, in dem das Passwort zurückgesetzt und neu vergeben werden muss. Sei es, weil man es vergessen hat oder weil die Passwortanforderungen gestiegen sind. Dann muss die Änderung bestätigt werden und die dazu gehörige Mailadresse, an die der Service einen Bestätigungslink schickt, ist nicht mehr gültig.
Für Provider ist es wichtig, die eigenen Systeme nicht überlasten zu lassen. So greift man auf bekannte Spamlisten zurück und vertraut diesen vielfach. So lassen sich einzelne Mailadressen oder auch alle Mails, die von einem Domainnamen versendet werden, blockieren.
Doch der Aufwand hat seinen Preis und schlägt darin nieder, dass mehr Ressourcen gebraucht werden, mehr Server und somit mehr Strom.
Beliebte Gegenmaßnahme: Blockade des IP-Bereichs
Stellt sich heraus, dass einzelne Server oder ganze Serverfarmen ohne Ende Spammails versenden, blockiert man diese Server anhand der IP-Adresse. Dies ist für Mailprovider kritisch. Wird die IP-Adresse eines Servers gesperrt, mit dem viele User arbeiten, kann keiner von ihnen mehr Mails an andere Server schicken, die die eine solche IP-Sperre umgesetzt haben.
Aber Spammer können auch diese Wege umgehen: Spam wird oft von gekaperten Servern oder gehackten Mailaccounts heraus versendet. Zwar greifen ab einem gewissen Zeitpunkt die Antispammaßnahmen und die Mailadresse ist „verbrannt“. Doch bis zu diesem Zeitpunkt sind zehntausende Mails bereits versendet worden.
Stellt der Spammer oder die Spammerin fest, dass seine beziehungsweise ihre Spammails nicht mehr ankommen, wechselt er oder sie die Server-IP und die Mailadresse. Dann lohnt es sich aus deren Sicht, den Inhalt zu variieren – und weiter geht’s.
Natürlich werden Spamfilter, egal wie sie arbeiten, immer wieder neu herausgefordert. Der Versand an sich ist billig. Die Verfügbarkeit von gehackten Mailaccounts aber ist schon knapper. Daher wird es sich lohnen, spamversendende E-Mailadresse über die Abuse-Adresse zu melden. Leider ist dies recht zeitaufwendig.
Auch Methoden, die auf maschinellem Lernen basieren, kommen an Grenzen, wenn zu wenig Information vorhanden ist. Diese Verfahren benötigen Informationen, die in der Vergangenheit generiert worden ist. Noch nicht gesehene Muster können nur mit relativ hoher Unschärfe verarbeitet werden. Die Fehlerrate steigt dann.
Ständige Variation der Muster
Ähnlich verhält es sich, wenn sehr wenig Information in der Mail selbst ist. Das kommt bei Phishingmails oder Werbemails sehr oft vor. Solche Mails sind nach Spezifikation korrekt geformt oder inhaltlich extrem reduziert und angereichert mit etwas Blindtext aus irgendwelchen Quellen.
Hier kann es passieren, dass nicht genügend Faktoren entwickelt oder Kriterien gefunden werden können, um eine neue, unbekannter E-Mail gut zu kategorisieren. Im Zweifelsfall würde man die Mail durchstellen.
Natürlich ist es sehr nervig, immer wieder Spammails mit gleicher Charakteristik zu erhalten. Was kann man tun?
Es gibt auf Empfängerseite einige Möglichkeiten, eingehende E-Mails selbst zu filtern. Bei goneo haben wir eine Webmail-Anwendung, die in der Lage ist, vom User beziehungsweise der Userin angelegte Regeln abzuarbeiten. Auf diese Weise kann man sich eigene Filter anlegen.
Wenn man das Spamgeschehen etwas beobachtet hat, wird man die Gemeinsamkeiten der Mails festgestellt haben. Dies ist der Schlüssel zu einem Filter, der auf Regeln basiert.
Mit Roundcube, der Webmailanwendung, die von goneo verwendet wird, kann man diese Gemeinsamkeiten in eine Filterregel eingeben. Falls die Filterregel von einer eingehenden Mail erfüllt wird, wird eine festgelegte Aktion ausgeführt. Beispiel: Sollte eine Mail den Begriff „rezeptfrei-apotheke“ beinhalten, wird die Mail gelöscht.
Es stehen eine Reihe von Aktionen zur Verfügung.
Überprüfung anhand der Domain
Mittlerweile wurden einige Verfahren entwickelt, mit denen der empfangende Mailserver prüfen kann, ob der sendende Server überhaupt E-Mails für eine bestimmte E-Mailadresse absenden darf.
Zu dieser Gruppe an Verfahren gehört SPF. Die drei Buchstaben stehen für „Sender Policy Framework„. Damit das funktioniert, wird in den Domainparametern ein entsprechender Datensatz (eine definierte Zeichenfolge als TXT-Eintrag) hinterlegt. Damit das beim serverseitigen Weiterleiten kein Problem gibt, hat goneo dem SPF-Mechanismus noch ARC („Authenticated Received Chain„) zur Seite gestellt.
DKIM (DomainKeys Identified Mail.) geht noch weiter kann mit einem asymetrischen Schlüsselaustausch die Domain des sendenden Servers überprüfen.
Schlagen diese Prüfungen fehl, ist die Wahrscheinlichkeit höher, dass es sich um Spam handelt. Doch nicht alle Mailservices unterstützen diese Mechanismen.
Grenzen der Maßnahmen: Einen Absender zu sperren hilft nur bedingt
Das Filtern kann Tücken haben. Beispiel: Man erhält immer wieder eine Mail, die scheinbar immer vom gleichen Absender kommt. Somit scheint es naheliegend zu sein, diese Adresse zu blockieren.
Natürlich kann man mit der goneo-Webmail-Anwendung, einen bestimmten Absender sperren. Dabei ist es aber wichtig, die richtige Absenderangabe zu finden. In einer E-Mail muss der angezeigte Name nicht dem tatsächlichen Absender – genauer gesagt: der absendenden E-Mailadresse – entsprechen.
Betrachten wir ein Beispiel: Dies ist ein Screenshot von Microsoft Outlook – der „Posteingang“, hier der „Junk“-Ordner:
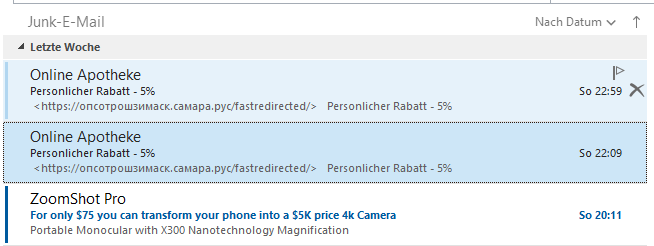
Es scheint in dieser Ansicht, als kämen die beiden blau bzw. leichtblau hinterlegten Mails vom gleichen Absender, der sich fälschlich als „Online Apotheke“ identifiziert. Schaut man genauer hin, stellt man fest, dass diese Mail aus unterschiedlichen Quellen stammen.


Oftmals fällt die Filterung von Absenderadressen dadurch schwer. Man muss diesen angezeigten Empfängernamen und die in eckigen Klammern stehende Absenderadresse unterscheiden. Jede Mailprogramm stellt diese Angaben unterschiedlich dar.
Anzeige in goneo-Webmail (auf Roundcube-Basis)
Hier ein ähnliches Spam-Beispiel aus Roundcube. Hier sind eingehende Mails so dargestellt:
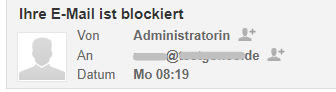
Im E-Mailbereich sehen wir zunächst nur die angezeigte Adresse in lesefreundlicher Form. Diese bezeichnet man gelegentlich als „friendly from“, weil sie im Normalfall schöner aussieht. Der absendende Nutzer/die absendende Nutzerin kann aber an dieser Stelle einen beliebigen Text angeben. Er oder sie könnte auch eine Zeichenfolge verwenden, die wie eine E-Mailadresse aussieht. Erst wenn man in Roundcube mit der Maus über diese Angabe fährt, erscheint die echte E-Mailadresse, von der die Mail auf den Weg gebracht wurde.
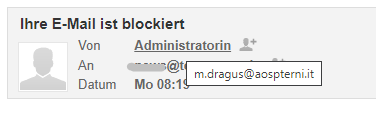
In Roundcube muss man mit der Maus über die Absenderangabe fahren, damit man die E-Mailadresse erkennt, von der die Mail versendet worden ist.
Hilfreicher Blick in die Headerdaten
Man kann auch etwas tiefer gehen und sich den Mail-Header ansehen. Es gibt im Web einige Dienste, die etwas helfen, zum Beispiel hier. Zunächst hilft es, den Mailheader zu finden und zu kopieren.
Leider ist das Verfahren in jedem E-Mail-Programm anders. Bei Microsoft Outlook findet man den Zugriff über die Einzelansicht der betreffenden Spam-Mail. In aktuellen Outlookversionen klickt man auf „Datei“ im Hauptmenü und in diesem Umfeld dann auf „Eigenschaften“. Die Headerdaten stehen hier im Abschnitt „Internetkopfzeilen“.
Für GMail ist das hier beschrieben, für Web.de oder GMX hier. In Roundcube bzw. goneo-Webmail öffnet man die betreffende Mail mit einem Doppelklick und nutzt dann im Menü oben den Punkt „Quelltext“, zu finden im Pulldown unter „mehr“.
Im Prinzip kann man die Headerdaten direkt lesen. Es handelt sich um ein einfaches Textformat. Die Interpretation wiederum ist nicht trivial. Das gilt umso mehr wenn einige Antispamfunktionen im Mailserver oder auf dem Weg aktiv waren. Einige hinterlassen Einträge. die allerdings wenig normiert sind. Dies kann die Anzahl der Kopfzeilen sehr erhöhen.
Ein echtes Beispiel zeigt: So laufen Regeln ins Leere
Hier ein echtes Beispiel eines Headers einer Spammail, wobei Server-IP- und Empfängerdaten „ge-ixt“ sind (xxxxxxx@xxxxxxx.cc, yyy.yyyyyy.yy.cc, zz.zzzzz.zz). Auch der Hostname des Empfänger ist umbenannt in „abcedefg“
Received: from abcedefg.co (abcedefg.co [999.888.777.66])
by zz.zzzzz.zz (Postfix) with ESMTP id 56DAF10A1E8D
for <xxxxxxx@xxxxxxx.cc>; Tue, 1 Mar 2022 23:37:41 +0100 (CET)
Date: Tue, 1 Mar 2022 17:31:52 -0500
From: PhysioTru <info@abcedefg.co>
MIME-Version: 1.0
Precedence: bulk
To: <xxxxxxx@xxxxxxx.cc>
Subject: The Most Dangerous Food In America?
Message-ID: <4HAH2iYyzWEmwH9tgczHrZTZnQKUYfvEJ3P2QUCY3FI.i2Jvy4_hZi13CxCRt813CM7gW_1QtqG2EuKSfh0fbYg@abcedefg.co>
Content-Type: text/html; charset="ISO-8859-1"
Content-Transfer-Encoding: quoted-printable
X-Rspamd-Queue-Id: 56DAF10A1E8D
X-Rspamd-UID: 03f26e
X-Rspamd-SPAM-Probability: *****
Return-Path: info@abcedefg.co
X-MS-Exchange-Organization-PRD: abcedefg.co
X-MS-Exchange-Organization-SenderIdResult: Fail
receiver=yyy.yyyyyy.yy.cc;
client-ip=10.0.aaa.bbb; helo=zz.zzzzz.zz;
X-MS-Exchange-Organization-Network-Message-Id: 72410629-d47f-4327-828d-08d9fbd41c50
X-MS-Exchange-Organization-AuthSource: yyy.yyyyyy.yy.cc
X-MS-Exchange-Organization-AuthAs: Anonymous
Hier wurde offenbar ein E-Mailkonto gehackt und zum Versand der Spammails verwendet. Die Headerdaten lassen ohne dass weitere Informationen herangezogen werden, nur bedingt einen Schluss darauf zu, inwieweit diese Mail als Spam einzuordnen ist. An sich sind die Headerinformationen plausibel. Die Message-ID sieht korrekt aus.
Erst durch menschliches Zutun, oder unter Umständen maschinell durch KI-Methoden unterstützt, könnte man bei der Absendeadresse stutzig werden: PhysioTru <info@abcedefg.co>. Das sogenannte „friendly from“ („PhysioTru“) will nicht so recht zur Mailadresse passen. Das „wissen“ einfache Algorithmen aber nicht.
So kommen unerwünschte Mails durch die Filter
Das Perfide ist nun, dass Mails bestimmter Art und Weise es schaffen, durch verschiedene Spamfilter zu gelangen. Einerseits deswegen, weil die Kopfdaten plausibel aussehen. Auch die Serverchecks funktionieren. Zudem ist die echte, absendende Adresse bislang nicht als problematisch aufgefallen.
Sobald sich zeigt, dass die E-Mailadresse auf Spamfiltern gelandet ist oder vom Serverbetreiber blockiert wird, nehmen die Spammer einfach den nächsten gehackten Mail-Account, lassen „friendly from“ gleich und variieren den Inhalt ein wenig. So kann man beim Empfänger nervige, aber werbewirksame Penetranz erzeugen.
Tipp: Bei goneo kannst du im goneo-Webmailer entsprechende Filter und Regeln anlegen. Bitte achte darauf, dass du die Regeln „serverseitig“ anwendest. Damit übernimmt der Mailserver die Arbeit. Im Gegensatz dazu lassen sich Filter auch „clientseitig“ anwenden. Das bedeutet, dass die Anwendung oder die Webanwendung aktiv, d.h. geöffnet sein müssen. Erst dann werden die Filter und Regeln angewendet. Um Mails vorzusortieren, ist die serverseitige Bearbeitung die bessere Wahl.
Guten Tag
Von Ihnen kommen verschieden Arten von Informationen aber kein vernünftiger Ansatz was man dagegen tun kann.
Viele Anti-Spam-Maßnahmen laufen serverseitig. So die Klassifizierung eingehender E-Mails als Spam oder Nicht-Spam. Die Kriterien für solche Systeme kann man nur ändern, wenn man selbst einen Mailserver betreibt. Aus Usersicht hat man die effektivsten Möglichkeiten in Form von SIEVE-Regeln in der Hand. Mit der Webmail-Implementierung auf webmail.goneo.de können goneo-Kunden eigene Regeln anwenden. Dieser Aspekt ist im Blogbeitrag ja auch beschrieben. Allerdings muss man die Filterkriterien zunächst gewinnen, um dann entsprechende Regeln formulieren zu können. Dies ist tatsächlich nicht trivial. Wir geben dem Blogbeitrag den Status „Re-optimierung“ und werden ihn demnächst überarbeiten, um solche Take-aways hervorzuheben.
Wir haben den Artikel auch dahingehend aktualisiert.
Guten Tag!
Zur Geschichte:
Einleitend verweise ich darauf hin, dass es durchaus eine griffige delikate Definition für „Spam“ gibt: „Frühstücksfleisch“. (abgeleitet von „Spiced Ham“)
Spam hat eine ca. 80-jährige gustatorische Tradition beginnend im analogen Zeitalter.
Für die ältere analog-digitale Generation wurde diese Tradition mit Auftauchen der Rechner im privaten Bereich weitergepflegt, indem morgens / vormittags vor dem Personalrechner ein Lagerfeuerchen entfacht wurde, um die Atmosphäre zu vergemütlichen und dabei Spam nebenbei zu verspeisen.
Die Schuldzuweisung für die Übertragung dieser Tradition in das digitale Zeitalter erfolgt in Richtung Monty Python. Diese haben einen schrillen analogen Sketch zu Spam produziert. (vgl. https://www.youtube.com/watch?v=ycKNt0MhTkk) Der Rest entwickelte sich so, wie wir das heutzutage kennen.
Zum Artikel:
Ich begrüße, dass solche populäre Themen wie in diesem Artikel ausführlich ange- und besprochen werden. Durch den informativen Umfang leidet ein wenig die Übersichtlichkeit für Nutzer an den stationären Desktop-Anlagen, da das Design des Textes eher der Mobile-First-Strategie folgt.
1. Abhilfe könnte aus meiner Sicht ein kleines Inhaltsverzeichnis am Artikelanfang mit Links zu den entsprechenden Sprungmarken (HTML-Anker) schaffen, damit der Leser sich am Anfang umgehend vorab orientieren kann. So könnte der Artikel ggf. mehrzeitig gelesen und dabei die entsprechende Fortsetzungsstelle im Inhaltsverzeichnis gezielt angesprungen werden.
2. Ein weiterer Vorschlag wäre zudem das Zusammenfassen des Inhalts am Anfang (in der wissenschaftlichen Literatur wird dafür eher das Ende bevorzugt), da ggf. ein gezieltes Interesse geweckt werden kann, sich tiefergehend mit den weiteren Ausführungen im Detail (und der Lösungen) zu beschäftigen.
Fazit:
Alles ist eine Frage der Strukturierung. Bei der digitalen Pan-Reizüberflutung sollte darüber nachgedacht werden, den Zugang zu hilfreichen textlichen Angeboten gezielt anzubieten, um den geneigten Leser schon früh zu signalisieren, dass der Inhalt für ihn relevant ist oder nicht. Dann sind längere Artikel kein potentielles Hindernis für den reizüberfluteten Leser.
Hallo zusammen,
könnte man bei goneo auch den spamfilter ähnlich zu spamassassin so konfigurieren, dass dieser automatisch anhand von existierenden spam emails lernt (welche der nutzer explizit in einen spam ordner ablegt)? Dadurch würde die Trefferrate beim Filtern von Spam-Mails deutlich verbessert.